- Published on
Project Planning with Directed Graphs
- Author
-
-
- Name
- Posts
- Posts
-

I recently spent a week locked in a boardroom with my management team and chairman developing our company strategy for short, medium, and long-range horizons. At one point during that week I stumbled upon a new way of representing and evaluating choices between different projects, each with different resource requirements and benefiting different customers or segments. At its core, it's a directed graph.
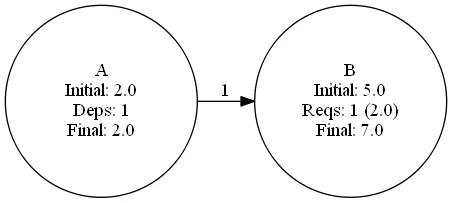
In this simplest of examples, there's a project A which costs 2 units. Project B depends upon 100% of A and itself costs 5 units. What does B really cost? B + 1.0 * A = 5 + 2 = 7 units.
Simple enough, right? Nodes are projects, and have costs. Edges are dependencies between projects, and have weights. The full cost of any project is the weighted sum of all its dependencies and its own internal cost.
Simple enough, right? Nodes are projects, and have costs. Edges are dependencies between projects, and have weights. The full cost of any project is the weighted sum of all its dependencies and its own internal cost.
Here's a more complex example.
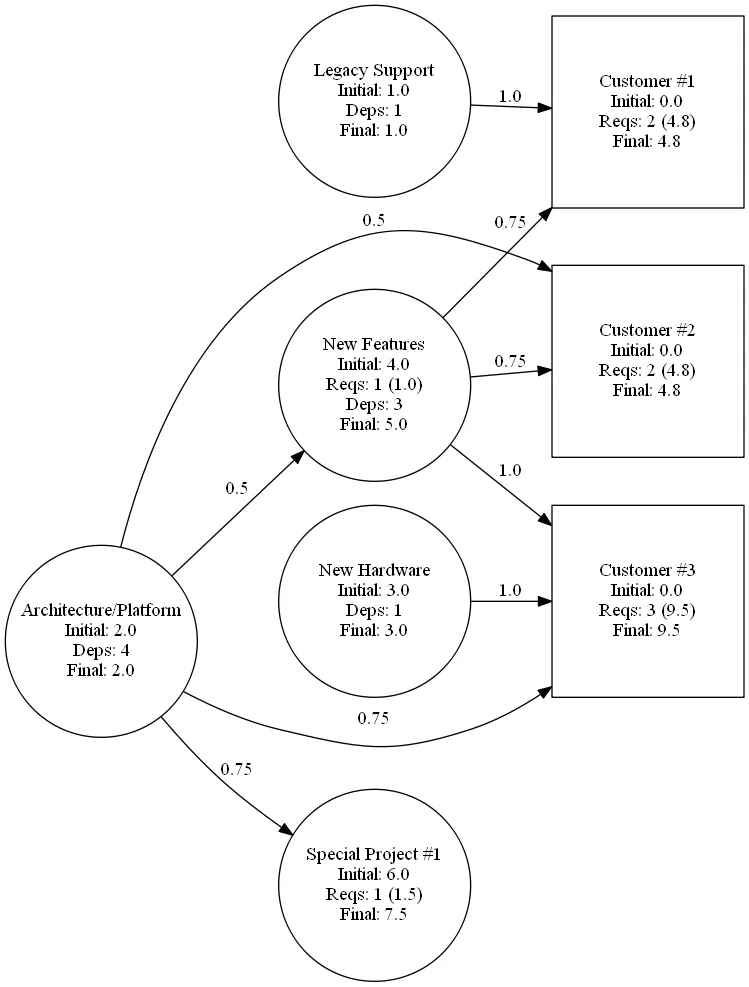
Here we have more projects, direct and indirect dependencies with varying weights, and customer-facing projects or outcomes (shown as squares).
If we pick on the Customer #3 project (which has no base cost for itself), we see it requires 100% of the New Hardware project (cost = 1.0 * 3 = 3), 75% of the Architecture/Platform project (cost = 0.75 * 2 = 1.5), and 100% of the New Features project - which itself needed 50% of the Architecture/Platform project too. That bumped the New Features project up from an initial cost of 4.0 to a true cost of 5.0, leaving Customer #3 with a total cost of 9.5.
But wait! We're double-counting there. Surely the Customer #3 project doesn't need 75% of the Architecture/Platform project directed and also another 50% indirectly via the New Features project?
Well... maybe. Or perhaps this tool only makes sense if you agree not to add dependencies beyond one 'layer'? There's an element of biomagnification going on here anyway, since the final costs of all customer-facing projects total to more than the total cost of all the other projects anyway.
At any rate, what I found in practice was that this way of visualising things had the immediate effect of halting an argument that all our customers were equally important. In our example not so different from this picture, it immediately showed that one customer had by far more costs than any other. Even though many of the requirements were shared - something this view also reveals - the disparity was not what our sales folks thought. And when one customer costs you more, it had better pay you more to make up for it!
I'm interested to explore this idea a bit more, and see if it is of real use in the business world or whether I just stumbled across a suitable piece of business bullshit at the exact right moment to win an argument. I suspect there may be some interesting use-cases that involve normalising the out-edges and/or in-edges (i.e. summing them up and dividing each by the total, so the weights sum to 1.0).
If you're interested in playing around with this concept, my sample code in Python is attached below.
If we pick on the Customer #3 project (which has no base cost for itself), we see it requires 100% of the New Hardware project (cost = 1.0 * 3 = 3), 75% of the Architecture/Platform project (cost = 0.75 * 2 = 1.5), and 100% of the New Features project - which itself needed 50% of the Architecture/Platform project too. That bumped the New Features project up from an initial cost of 4.0 to a true cost of 5.0, leaving Customer #3 with a total cost of 9.5.
But wait! We're double-counting there. Surely the Customer #3 project doesn't need 75% of the Architecture/Platform project directed and also another 50% indirectly via the New Features project?
Well... maybe. Or perhaps this tool only makes sense if you agree not to add dependencies beyond one 'layer'? There's an element of biomagnification going on here anyway, since the final costs of all customer-facing projects total to more than the total cost of all the other projects anyway.
At any rate, what I found in practice was that this way of visualising things had the immediate effect of halting an argument that all our customers were equally important. In our example not so different from this picture, it immediately showed that one customer had by far more costs than any other. Even though many of the requirements were shared - something this view also reveals - the disparity was not what our sales folks thought. And when one customer costs you more, it had better pay you more to make up for it!
I'm interested to explore this idea a bit more, and see if it is of real use in the business world or whether I just stumbled across a suitable piece of business bullshit at the exact right moment to win an argument. I suspect there may be some interesting use-cases that involve normalising the out-edges and/or in-edges (i.e. summing them up and dividing each by the total, so the weights sum to 1.0).
If you're interested in playing around with this concept, my sample code in Python is attached below.
#!/usr/local/bin/python3
# -*- coding: utf-8 -*-
import subprocess
from collections import defaultdict
import platform
input_file = "test.dot"
output_file = "test.png"
dot_cmd = "dot -Tpng"
if platform.system()=="Windows":
open_cmd = ""
reopen = False
else:
open_cmd = "open"
reopen = True
ARCH = "Architecture/Platform"
FI = "Special Project #1"
HW = "New Hardware"
LEG = "Legacy Support"
FEAT = "New Features"
"""
"type": string; one of ["project", "customer"], defaults to "project" if missing or a string not in this list.
"reqs": dictionary from "name" -> proportion_of_use.
"val": float; quantity to propagate to dependent nodes, defaults to zero.
"""
data = [
{"name": FEAT, "val": 4, "reqs": {ARCH:0.5}},
{"name": ARCH, "val": 2},
{"name": HW, "val": 3},
{"name": LEG, "val": 1},
{"name": FI, "val": 6, "reqs": {ARCH:0.75}},
{"name": "Customer #1", "type": "customer", "reqs": {FEAT:0.75, LEG:1.0}},
{"name": "Customer #2", "type": "customer", "reqs": {ARCH:0.5, FEAT:0.75}},
{"name": "Customer #3", "type": "customer", "reqs": {ARCH:0.75, HW:1.0, FEAT:1.0}}
]
def main():
customers = []
edges = []
dot_script = []
plist = defaultdict(list) # Dictionary of nodes to parents.
dgraph = defaultdict(lambda i: defaultdict(str)) # Dictionary of nodes and their dependency-chain values.
pnodes = [] # List of nodes that still need to propagate values up the chain. (Initially the leaf nodes.)
# Build up relationship graph from data, summing weighted values along dependency chains.
# Pass-1: Collect leaf nodes, and invert the tree into 'plist', which captures parents of each node.
for row in data:
name = row.get("name", None)
if name:
dgraph[name] = {
'min':row.get("val", 0.0),
'max':row.get("val", 0.0),
'orig': row.get("val", 0.0),
'in': 0,
'out': 0
}
reqs = row.get("reqs")
if reqs:
for n, v in reqs.items():
plist[n].append((name, v))
else:
pnodes.append(name) # Initially, nodes that need to propagate up are just the leaves.
# Pass-2:N: Start at leaves, propagate values back up.
while(pnodes):
pnodes_next = []
for row in data:
name = row.get("name", None)
if name in pnodes:
parents = plist[name]
for p, v in parents:
dgraph[name]['out'] += 1
dgraph[p]['min'] += dgraph[name]['orig'] * v # orig_leaf_val * edge_weight
dgraph[p]['max'] += dgraph[name]['max'] * v # final_leaf_val * edge_weight
dgraph[p]['in'] += 1
pnodes_next.append(p)
pnodes = list(set([p for p in pnodes_next]))
# Collect nodes that are customers, and all edges.
for row in data:
name = row.get("name", "NAME_MISSING!")
if row.get('type') == "customer":
customers.append(name)
reqs = row.get("reqs")
if reqs:
for n, v in reqs.items():
edges.append(" \"%s\" -> \"%s\" [label=\"%s\"];" % (n, name, v, ))
# Create dot-syntax.
dot_script.append("digraph G {")
dot_script.append(" rankdir=LR;")
if customers:
dot_script.append(" node [shape = square]; %s;" % (' '.join(["\"%s\"" % i for i in customers]), ))
dot_script.append(" node [shape = circle];")
for e in edges:
dot_script.append(e)
for k, v in dgraph.items():
dot_script.append(" \"%s\" [fixedsize=true; width=2; label=\"%s\nInitial: %.1f\n%s%sMin: %.1f\nMax: %.1f\"];"
% (k, k, dgraph[k]['orig'],
"Reqs: %d (%.1f)\n" % (dgraph[k]['in'], v['max']-dgraph[k]['orig'], ) if dgraph[k]['in'] else "",
"Deps: %d\n" % (dgraph[k]['out'], ) if dgraph[k]['out'] else "",
v['min'], v['max'], ))
dot_script.append("}")
output = '\n'.join(dot_script)
# Write to dot file.
with open(input_file, 'w+') as file:
file.write(output)
# Generate PNG of graph and open it.
subprocess.call("%s %s > %s" % (dot_cmd, input_file, output_file, ), shell=True)
if reopen:
subprocess.call("%s %s" % (open_cmd, output_file, ), shell=True)
if __name__ == '__main__':
main()0 Comments